
Unzulängliche Projektorganisation ist eine Hürde bei der Innovation mittels AI
Bei der Anwendung von agilen Vorgehensmodellen, wie Scrum oder SAFe, hat sich in mehreren Projekten gezeigt, dass KI-Projekte oft andere Herausforderungen mit sich bringen und daher einen anderen Ansatz bei der Durchführung von agilen Projektmethoden erfordern. Für die Bewältigung dieser Herausforderungen haben wir uns crossfunktional mit Kollegen:innen aus Agile und Data and Analytics zusammengetan, um Lösungswege herauszuarbeiten. Dazu haben wir ein Framework entwickelt, das die Herausforderungen und Probleme beim agilen Management von KI-Projekten adressiert.
Im Folgenden werden wir zunächst die Keypoints, die Herausforderungen und daraus resultierenden Empfehlungen erläutern.
Unser Erfolgsrezept zusammengefasst
- Definieren Sie den Projekterfolg anhand einer eigenen Metrik, die sich an Ihrem Business Value und Ihren Business Goals orientiert.
- Arbeiten Sie MVP-getrieben mit Hypothesenbildung.
- Arbeiten Sie innerhalb einer Iteration nach CRISP-DM.
- Etablieren Sie eine Fail-Fast / Fast-Success Culture im Team und Management.
- Setzen Sie auf Tools und Infrastruktur zur Automatisierung über den gesamten Produktlebenszyklus hinweg mit einer konsequenten MLOps-Kultur.
Herausforderungen beim Projektmanagement von AI-Projekten
Was unterscheidet KI-Projekte von anderen IT-Projekten, sodass wir immer wieder feststellen, dass es an dem Projektvorgehen hapert?
Inhärente Erfolgsunsicherheit bei KI-Projekten
Bei einem Softwareentwicklungsprojekt kann das Team einschätzen, ob eine Lösung technisch machbar ist. Das ist nicht immer einfach, aber gut möglich. Anders verhält es sich bei KI-Projekten. Wir werden stets vor die Frage gestellt: „Geben die Daten überhaupt das her, was wir damit erreichen wollen?“. Nicht selten mussten wir nach einer intensiven Datenanalyse und Vorstudie feststellen, dass die Daten nicht ausreichen, um das Projekt zum Erfolg zu führen. Dass KI-Projekte mit einer verstärkten Erfolgsunsicherheit behaftet sind, sehen wir mit Berichten aus dem Markt bestätigt.
"Mit 10-20% Erfolgswahrscheinlichkeit bei marktführenden Unternehmen haben KI-Projekte eine inhärente Erfolgsunsicherheit.“
Projekterfolg ist nicht anhand der Anforderungen und Qualität des Systems messbar
In der Softwareentwicklung können wir Erfolg anhand der erfüllten Anforderungen, der zeitlichen Dauer und den entstandenen Kosten messen. Es ist uns auch möglich, kontinuierlich im Projektverlauf die Qualität der Software durch vordefinierte Metriken und Tests sicherzustellen. Anders verhält es sich bei KI-Projekten. Wir können rein technisch keine hundertprozentige Genauigkeit bei der Vorhersage eines Modells erreichen. Entsprechen haben wir hier die Herausforderung, ein System bewerten zu müssen, dass hin und wieder Fehler macht. Metriken, wie Genauigkeit, Präzision, F-Score, etc. geben zwar Auskunft über die Performance eines Modells, diese sind aber ungeeignet, um die Erfüllung der geschäftlichen Anforderungen zu beurteilen. Beispielsweise sind die Kosten für einen nicht erkannten Betrug höher als für einen als fehlerhaft erkannten nicht Betrugsfall. Auf der einen Seite steht ein einzelner unzufriedener Kunde, der sich an das Unternehmen zwecks Klärung wenden muss, auf der anderen ein direkter monetärer Schadensfall. Der Projektfortschritt ist entsprechend nicht anhand dieser Metriken messbar. Um dennoch den Projekterfolg beurteilen zu können, muss die Bewertung angepasst werden.
Ob eine Story einen positiven oder negativen Einfluss auf das System hat, ist erst nach der Umsetzung bekannt
Ebenso bezieht sich diese Unsicherheit auf einzelne Stories innerhalb eines Projekts. Es ist vorher nicht abzuschätzen, wie sich z. B. ein Datenaufbereitungsschritt auf die Modellqualität und so auf das Projektziel auswirkt. So ist es bei KI-Projekten möglich, dass es bei der Durchführung der Datenaufbereitung zu Missverständnissen hinsichtlich der Fachlichkeit kommen kann. Dieses fehlende Verständnis kann einen negativen Einfluss auf die Modellperformance haben. Daher wird die Sprintplanung erschwert. Hier stellt sich die Frage: Wie können Stories priorisiert und eingeordnet werden, wenn der Nutzen für das Sprint- und Projektziel unklar ist?
Geänderte Anforderungen an Infrastruktur und Techniken
Insbesondere die im Unternehmen vorhandenen Infrastrukturen und Tools spielen hier eine wichtige Rolle. In der Softwareentwicklung ist ein Entwickler in der Lage autark auf seinem Laptop zu arbeiten. Dieser Luxus ist bei KI-Projekten nicht gegeben. Hier sind lange Laufzeiten bei der Datenaufbereitung und der Modellierung der Regelfall. In Domänen wie der Bilderkennung, können sogar die Laufzeiten mehrere Tage umfassen. Lange Feedbackzeiten reduzieren die Produktivität und erhöhen die Projektlaufzeit. Hier muss für die Projektmitglieder die Möglichkeit bestehen, parallel zu experimentieren und auf verteilten Clustern mit ausreichenden Ressourcen zu arbeiten. Viele Unternehmen haben bereits ein Kubernetes- oder Open Shift-Cluster oder nutzen Ressourcen bei einem Cloud Provider. Der Umgang mit diesen Ressourcen verlangt aber intensives Know-How, das in Machine-Learning-Projekten nicht vorausgesetzt werden kann. Durch den Einsatz von MLOps Tools und Technologien, die es ermöglichen, dass Data Scientisten und Machine Learning Engineers selbstständig auf dieser Infrastruktur arbeiten können, werden KI-Projekte massiv beschleunigt. Nicht länger ist der Laptop des Entwicklers der limitierende Faktor im Projekt, sondern die Analyse der Fachlichkeit und Daten.
„Sprechen Sie uns gerne zum Thema MLOps an!“
Heterogene KI-Teams bringen neue Herausforderungen
KI-Projekte sind von starker Heterogenität geprägt. Hier finden sich Projektmitglieder mit völlig unterschiedlichen Hintergründen und Expertisen zum ersten Mal für einen solchen Zweck im Projekt zusammen. So ist es insbesondere in unserem Banken- und Versicherungsumfeld normal, einen Experten aus der jeweiligen Fachdomäne, einen Data Scientisten mit verstärktem mathematischen Hintergrund und einen Softwareentwickler in einem Projekt zu haben. Die Chancen, voneinander zu lernen und gemeinsam durch verschiedene Erfahrungen und Blickwinkel Probleme zu lösen, sind groß.
Aber es birgt auch Risiken, die gemeistert werden müssen. Diese Heterogenität der Projektmitglieder spiegelt sich ebenso bei den Ansichten und Blickwinkeln wider. Das kann zu einem erhöhten Konfliktpotenzial führen. Ebenso sind die Arbeitsweisen meist andere. Die verwendeten Tools und Methoden unterscheiden sich je nach Hintergrund und Wissen stark. Finden wir hier keine gemeinsame Grundlage bezüglich Qualitätsbewusstsein, Prozesse und Tools, ist Chaos vorprogrammiert.
Unsere Empfehlungen
Lösungsvorschlag: Projekterfolg messen
Nicht ein statischer Wert, sondern der Business Value sollte über Erfolg oder Misserfolg bestimmen. Eine Aussage wie „Wir können 98% aller nicht Betrugsfälle und 95% aller Betrugsfälle richtig mit unserem KI-Modell klassifizieren“ lässt noch keinen Rückschluss auf den tatsächlichen Value für das Unternehmen zu. Daher empfehlen wir folgendes: Stellen Sie zu Beginn des Projekts eine Metrik aus geschäftlicher Sicht auf. Für die Betrugserkennung einer Versicherungsschadensmeldung kann eine sinnvolle Metrik zum Beispiel folgendes sein: die Prozesskostenersparnis im Verhältnis zu potenziellen nicht notwendigerweise ausgezahlten Beträgen. Insbesondere muss hier die geschäftliche Auswirkung der Modellperformance einbezogen werden. Listen Sie weiterhin nicht-funktionale Rahmenbedingungen auf, die Sie für einen Erfolg des Projekts sehen. Dadurch kann das Projekt in seinem Zielrahmen handlungsfähiger bleiben. So können Sie z. B. auch feststellen, dass Ihr KI-System zwar weniger Betrüger erkennt als eine klassische manuelle Prüfung, dafür aber massiv Prozesskosten eingespart werden. Ebenso lässt sich so die Bearbeitungszeit drastisch verkürzen. Im Endeffekt lässt sich das Projekt dennoch als ein eindeutiger Erfolg verbuchen.
Insbesondere darf hier nie vergessen werden, dass sich das Modell mit den Daten aus dem Produktionsbetrieb stetig verbessern lässt.
„Nicht ein statischer Wert, sondern der Business Value sollte über Erfolg oder Misserfolg bestimmen. Wir empfehlen: Stellen Sie zu Beginn des Projekts eine Metrik aus geschäftlicher Sicht auf.“
Um weitere Rahmenbedingungen für den Projekterfolg strukturiert erfassen und steuern zu können bietet sich der Einsatz des Objectives and Key Result Frameworks an.
Unsicherheiten bei den Stories durch MVP-getriebene Entwicklung Rechnung tragen
Agilität lebt von kurzen Iterationen, in denen Artefakte produziert und geprüft werden und stetig Wert für den Kunden geschaffen wird. In KI-Projekten können wir dieses Vorgehen nicht einfach übertragen. Anstatt einer Story, die nach der Umsetzung getestet und nach dem Deployment dem Nutzer direkt einen Wert stiften kann, können wir den direkten Value einer Story bei KI-Projekten nicht vor der Umsetzung abschätzen. Wir sehen keine Lösung, um den Impact einer Story auf den Erfolg im Vorhinein vorherzusagen. Daher empfehlen wir, die Risiken gezielt zu steuern und ein MVP- und hypothesengetriebenes Vorgehen zu wählen.
„MVPs fördern die Innovation und ermöglichen es, den Scope schnell anzupassen.“
Ziel des Projekts ist zu Beginn, ein Modell zu erstellen, das noch nicht den definierten Projekterfolg erfüllen muss, sondern beweist, dass sich ein grundsätzlich funktionierendes Modell erstellen lässt. Wird das erreicht, kann die Erfolgswahrscheinlichkeit des Projekts neu bewertet werden. Lassen die Daten z. B. nicht zu, dass ein sinnvolles Modell für den ursprünglich geplanten Use-Case generiert wird, kann an dieser Stelle das umgeschwenkt und ein anderer Use-Case verprobt werden.
Hypothesen erlauben eine Orientierung am Kompass unserer Vision und regelmäßige Zielanpassungen vorzunehmen. Stellen wir fest, dass die Ergebnisse vielversprechend sind, können die Investitionen in das Projekt erhöht werden. Im negativen Fall haben wir die Möglichkeit, entweder mit einer anderen Arbeitshypothese weiterzuarbeiten oder das Projekt zu stoppen.
„Hypothesenbildung und -prüfung müssen im Zentrum des Projektmanagements stehen.“
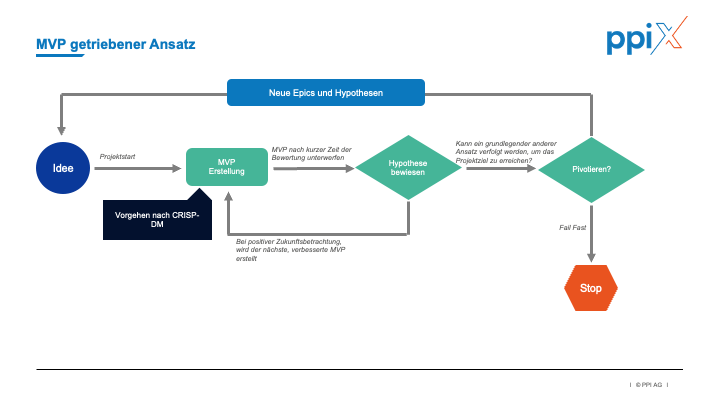
Ebenso kann dieses Vorgehen zu unternehmenskulturellen Anpassungen führen. Eine Fail-Fast/Fast-Success Culture muss sowohl vom Management als auch von den Projektmitarbeitern gelebt werden, um Zeit- oder Kostenüberziehungen zu vermeiden und die Motivation der Mitarbeiter aufrecht zu erhalten.
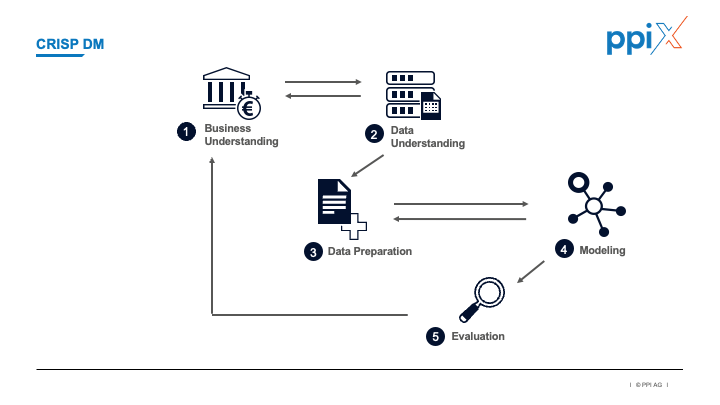
Innerhalb einer Iteration nach CRISP-DM arbeiten
Zur effektiven Entwicklung eines MVPs sollte das Vorgehensmodell CRISP-DM (CRoss Industry Standard Process for Data Mining) angewendet werden. CRISP-DM ist ein auch im Data Science-Bereich populäres Vorgehensmodell, das bereits 1999 veröffentlich wurde. Wir empfehlen innerhalb einer Iteration nach diesem Vorgehensmodell zu arbeiten. Die Phasen bestehen aus Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation und Deployment. CRISP-DM bietet sich aufgrund der klaren Arbeitsschritte und iterativen Ablaufs als Vorgehensmodell für die MVP Erstellung an. Deployment als Schritt im Vorgehensmodell kann für die reine MVP Erstellung ignoriert werden. Es findet seinen Platz nach der Bewertung des MVPs. In unserem Rahmenwerk wollen wir zuallererst beweisen, dass dieses Projekt erfolgreich sein kann.
Den reinen Einsatz von CRISP-DM für Projekte im Bereich der Künstliche Intelligenz und des Machine Learnings halten wir dennoch nicht für nicht ausreichend. Das Vorgehensmodell muss in einen größeren Kontext eingebettet werden. CRISP-DM allein trägt der inhärenten Erfolgsunsicherheit dieser Projekte nicht Rechnung. Ein kontinuierlicher Überprüfungsvorgang nach Erfolgsaussicht fehlt. Ebenso stellt CRISP-DM, anders als unser Vorgehen, nicht den Business Value in den Vordergrund.
MLOps-Techniken und -Kultur etablieren
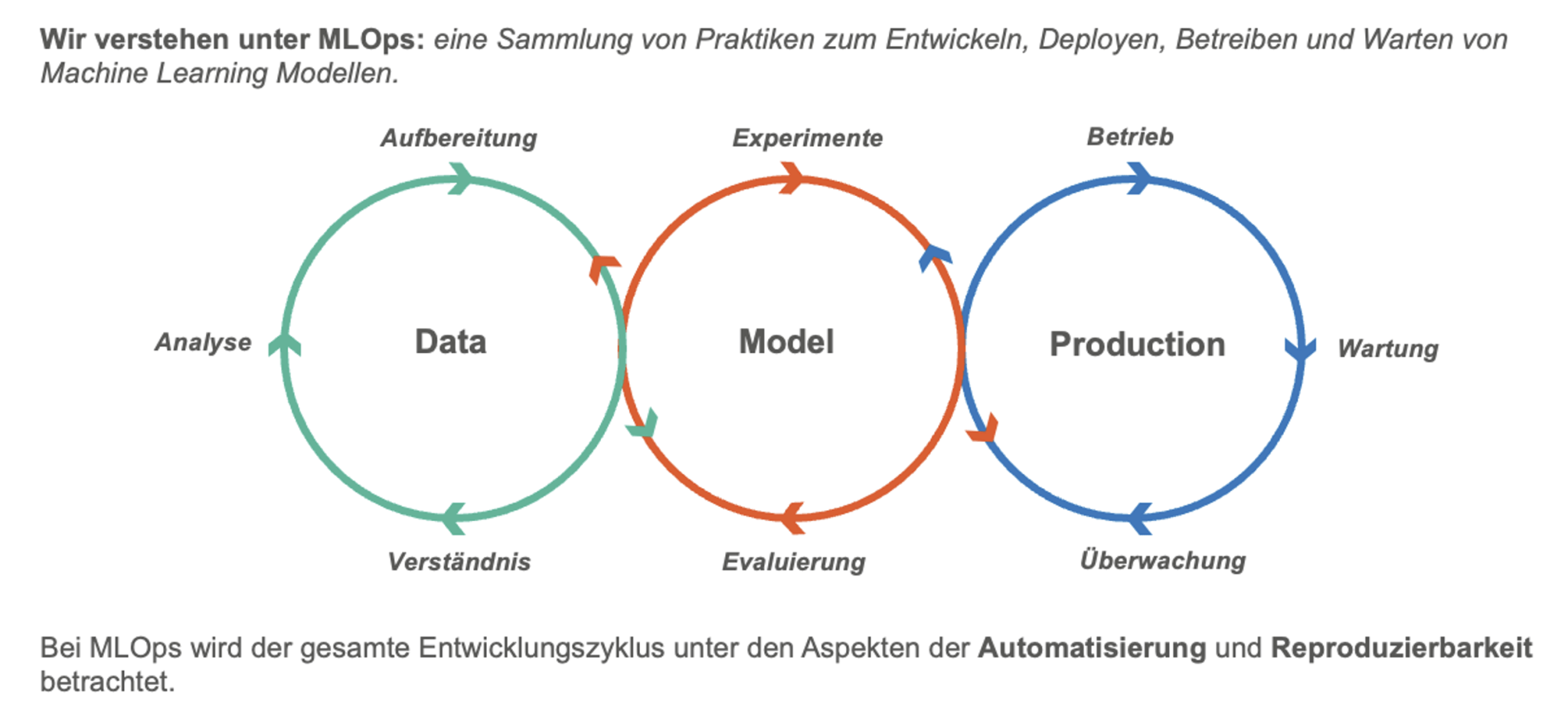
In der Softwareentwicklung ist DevOps, insbesondere Continuous Integration und Continuous Deployment industrieweit etabliert. Analog dazu hat sich im KI/Machine Learning Bereich der Begriff MLOps durchgesetzt. Ziel es ist, mithilfe verschiedener Tools und Praktiken, den Data Scientisten oder Machine Learning Engineer zu befähigen, den gesamten Entwicklungsprozess, von der Datenaufbereitung, über das Modelltraining bis hin zum Deployment auf einer verteilten Infrastruktur automatisiert und möglichst einfach zu gestalten. Damit wird die Arbeit des Teams massiv beschleunigt. Wir verstehen MLOps hier als Philosophie, den gesamten Machine Learning Entwicklungszyklus unter den Aspekten der Automatisierung, Reproduzierbarkeit und Dokumentation zu betrachten. Diese Philosophie muss von allen Projektmitgliedern gelebt werden.
„Die MLOps-Techniken und -Kultur müssen im Unternehmen etabliert sein.“
Crossover-Teams
Eine intensive Kollaborationskultur ist der Schlüssel zum Erfolg. Wir empfehlen hier klar, Pair-Programming auf alle Teilaspekte des Projekts anzuwenden und Projektmitglieder gemeinsam ihr Know-How in Zweierarbeit einzubringen. So lernen alle Projektmitglieder die Fachdomänen ihrer Kollegen kennen und Wissensmonopole werden aufgebrochen.
Fazit
Die Chancen, die Künstliche Intelligenz bietet, sind branchenübergreifend enorm. Es gibt keine Branche, die nicht von diesen Technologien profitieren kann, um einen entscheidenden Marktvorteil gegenüber der Konkurrenz zu erlangen. Mit unserem Vorgehen brauchen Sie keine Scheu vor den Herausforderungen zu haben. Nutzen Sie die schnellen, MVP-getriebenen Iterationen, um viele Ideen mit geringen Kosten auszuprobieren. Setzten Sie konsequent auf Automatisierung und MLOps für maximale Produktivität.
Gerne unterstützten wir Sie bei der Findung von Use Cases, dem Projektmanagement und der Durchführung von KI-Projekten mit unseren Spezialisten für Data Science und Machine Learning.



