
In der heutigen Zeit fallen immer mehr Daten an. Oft wird dieser Schatz in Unternehmen aber nur wenig genutzt. In der Konsequenz fehlen dem Management wichtige Kennzahlen zur Unternehmenssteuerung, die IT-Abteilung ist durch die Betreuung der Kernsysteme ständig überlastet und kann neue Anforderungen nur langsam umsetzen. Fachabteilungen sind aufgrund einer nicht ausreichenden Datengrundlage unzufrieden und von Agilität ist nicht viel zu spüren.
Wie kann man dies ändern?
PPI. X beantwortet diese Frage so:
- Die Erstellung des Data Warehouses muss konsequent automatisiert werden.
- Fachspezialisten müssen in der Lage sein, Berechnungen von Kennziffern selbst anzupassen und innerhalb sehr kurzer Zeit eigenständig produktiv zu nehmen.
- Die Rolle der IT-Abteilung muss sich ändern. Sie setzt nicht mehr jede einzelne fachliche Anforderung im Auftrag der Fachabteilung um. Stattdessen stellt sie eine Automatisierungsplattform bereit, auf der Fachspezialisten eigenständig arbeiten können. Bei komplexen Fragestellungen berät und unterstützt sie die Fachabteilung.
Um dies auch technisch umsetzen zu können, hat PPI.X den Data Vault Generator (DVG) entwickelt. Dieses Tool basiert auf Data Vault 2.0. Im Gegensatz zu anderen Generatoren automatisiert der DVG aber nicht nur die einfachen Prozesse, sondern das gesamte Data Warehouse einschließlich der fachlichen Logiken und der Befüllung von Datamarts. Auch weitere Anforderungen (zum Beispiel die DSGVO und die optimale Testunterstützung) werden dabei berücksichtigt.
Welcher Nutzen ergibt sich daraus für das Unternehmen?
Im traditionellen Data Warehouse stellen die Fachabteilungen ihre Anforderungen an die IT-Abteilung. Diese setzt sie einzeln um.
Durch die Vielzahl der Einzelanforderungen ist die IT überlastet und die Umsetzung dauert mehrere Wochen. Benötigte Kennzahlen stehen zu spät oder gar nicht bereit.
Durch Automatisierung können kleinere Änderungen sehr schnell umgesetzt werden. Davon profitieren sowohl die Fach- als auch die IT-Abteilung. Die Fachabteilung hat kleinere Anpassungen sehr schnell verfügbar. Die IT muss weniger Einzelanforderungen abarbeiten und kann sich auf Grundsatzthemen konzentrieren.
DVG-Arbeitsschritte
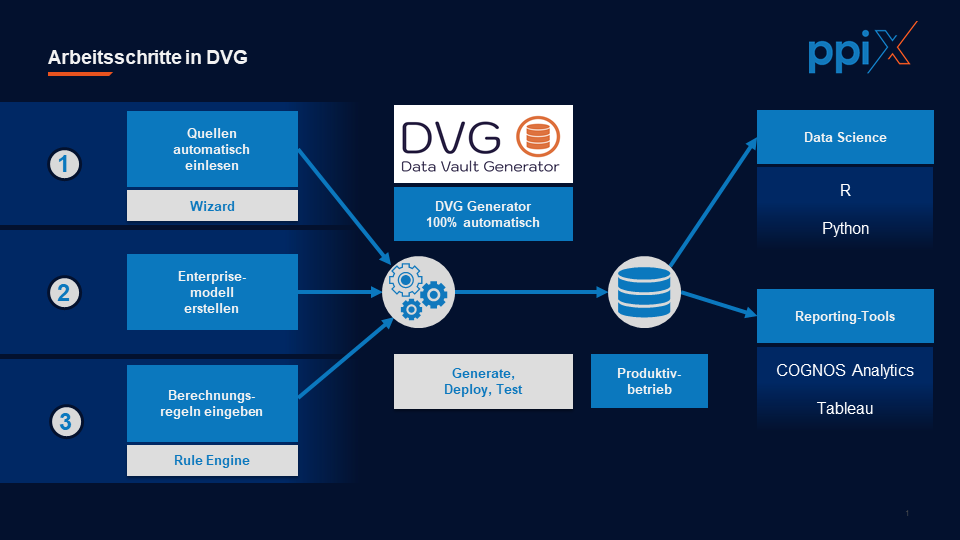
Im DVG werden zuerst die Datenstrukturen aus den vorgesehenen Liefersystemen mithilfe eines Wizards automatisch eingelesen.
Danach erstellen Datenmodellierer ein Enterprise-Modell, welches eine liefersystemübergreifende einheitliche Auswertung aller Daten ermöglicht. Dieses Modell kann iterativ inkrementell entwickelt werden. Man startet mit den wichtigsten Komponenten (zum Beispiel Kunden, Produkte und Verträge) und fügt sukzessive die weiteren Relationen hinzu. Solch eine inkrementelle Arbeitsweise wird durch Data Vault optimal unterstützt.
Gewünschte Kennziffern werden mithilfe einer Rule Engine berechnet. Die einzelnen Berechnungsregeln dieser Rule Engine können dabei durch Fachspezialisten selbstständig gepflegt werden.
Danach wird der Generator aktiv:
- Er erstellt allen notwendigen Code sowie Informationen zur Steuerung der Beladungsprozesse im Produktivbetrieb.
- Die Dokumentation inklusive detaillierter Data Lineage wird automatisch generiert.
- Darüber hinaus kümmert sich der DVG um das Deployment und den Test.
Im Ergebnis stehen die Unternehmensdaten für verschiedenste Zwecke zur Verfügung. Auswertungen mit Reporting-Tools, Data-Science-Analysen oder die maschinelle Belieferung von Folgesystemen werden somit optimal unterstützt.
Technische Umsetzung

Datenmodellierer/Fachspezialisten passen im DVG das Datenmodell oder die Geschäftsregeln in der Rule Engine an. Danach erzeugt der Generator den benötigten Code automatisch.
Das System erstellt selbstständig eine Kopie der aktuellen Produktivdaten, auf der die Änderungen eingespielt sind und ein Simulationslauf mit dem geänderten Code durchgeführt wird. Die Ergebnisse dieses Simulationslaufs werden mit dem ursprünglichen Produktivlauf verglichen und alle Änderungen detailliert aufgelistet. Da der Simulationslauf auf exakt denselben Ausgangsdaten wie der Produktivlauf beruht, kann man jetzt die Auswirkungen der vorgenommenen Änderungen fachlich bewerten und hat eine fundierte Entscheidungsgrundlage für die fachliche Abnahme. Die Abweichungsanalyse wird dabei durch ein intuitives Dashboard unterstützt.
Wenn die fachliche Abnahme erfolgt, wird die Änderung innerhalb weniger Minuten produktiv geschaltet. Dies erfolgt einfach durch den Austausch der produktiven Umgebung gegen die erstellte Kopie.
Fazit
Der DVG unterstützt die agile Data-Warehouse-Entwicklung optimal. Kleinere Anpassungen können Fachspezialisten selbstständig in wenigen Stunden produktivnehmen. Release-Zyklen werden deutlich verkürzt.



