
Kennen Sie folgende Situation?
- Aufgrund der Erkrankung des wichtigsten Testers aus der Fachabteilung verzögert sich der Abnahmetest des letzten Releases 2.0.0 auf unbestimmte Zeit. Die Fachabteilung bittet darum, die Testumgebung nicht zu verändern.
- Die Controlling Abteilung möchte gerne schon das aktuelle Release 2.1.0 testen. Ab Monatsende hat Controlling aufgrund des zu prüfenden Monatsabschlusses dafür keine Zeit mehr.
- Die Kollegen aus dem BI- Bereich schaffen es leider nicht, zum geplanten Produktionseinführungstermin alle Reports auf die geänderte Datamartstruktur des Release 2.0.0 umzustellen. Sie wünschen sich einen 4-wöchigen Parallelbetrieb der alten Version 1.9.0 und der neuen Version 2.0.0 in Produktion.
- Die DataScience Abteilung möchte ihre neu entwickelten Machine Learning Modelle trainieren und benötigt dazu ein erweitertes Datenmodell im DWH. Ob diese Erweiterung dauerhaft benötigt wird, hängt aber davon ab, ob das trainierte Modell gute Vorhersagen machen kann.
- Der Vorstand möchte für die Sitzung nächste Woche eine neue Kennziffer aus dem DWH haben. Diese Kennziffer wird für die Neuausrichtung der Unternehmensstrategie benötigt und hat oberste Priorität.
- Die Bafin verlangt von Ihnen als Bank, dass sie einen Stresstest durchführen und nachweisen, dass sie auch in einem worst case Markt-Szenario über genügend Eigenkapital verfügen.
- In der letzten Nacht gab es bei der produktiven Beladung des DWH ein Problem aufgrund einer versehentlichen Division durch 0. Dafür muss bis heute Abend ein Hotfix erstellt werden.
Dass verschiedene Stakeholder gleichzeitig viele und zum Teil widersprüchliche Anforderungen an ein DataWarehouse stellen, ist nicht ungewöhnlich.
Genau in diesen Fällen greift das Konzept der Multienvironment des DataVault-Generators von crossnative (DVG).
Multienvironment im DVG mit mehreren Konfigurationen:
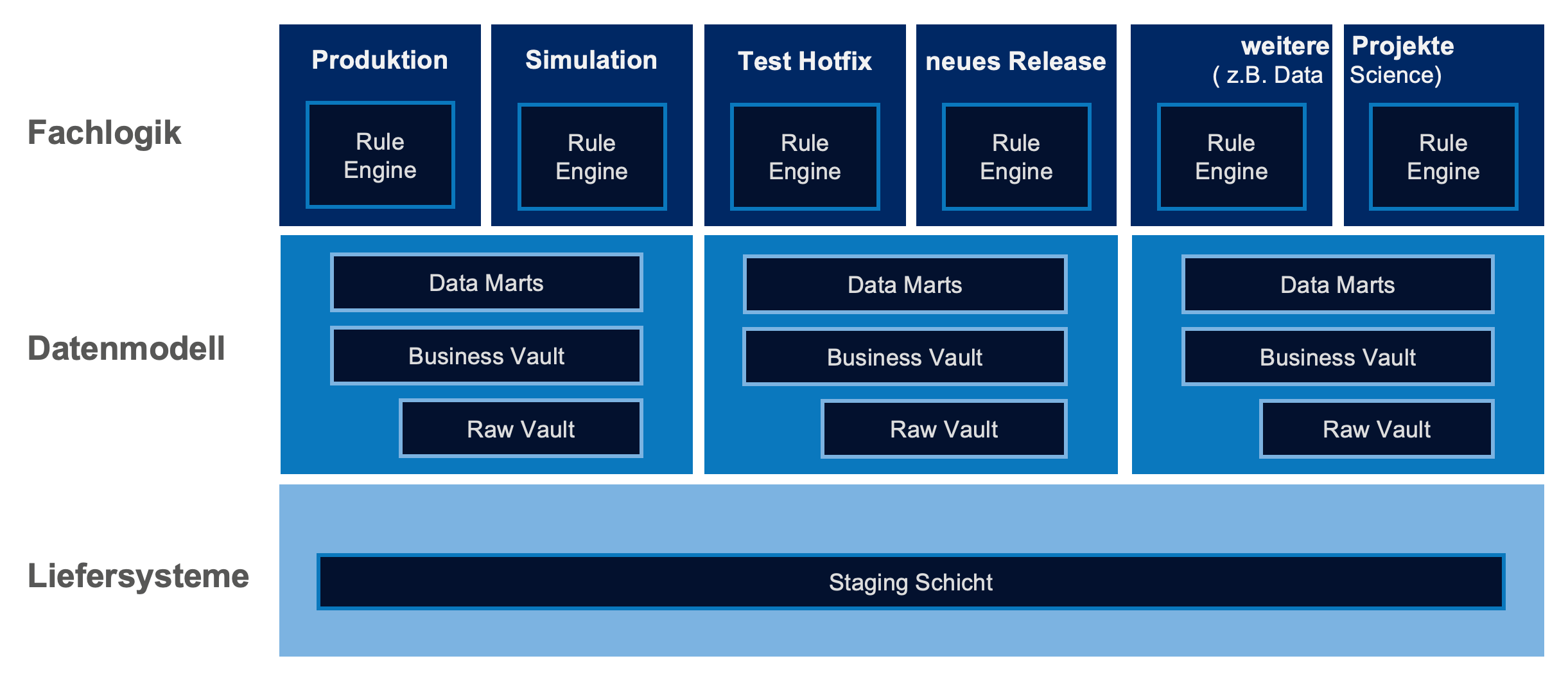
Prinzip Multienvironment des DVG
Die Architektur des DVG besteht aus drei Schichten:
- In der Staging Schicht werden die Original-Daten der Zuliefersysteme des DWH’s unverändert in vollständiger Historie gespeichert.
- Auf dieser Schicht können parallel mehrere DWH-Datenmodelle, bestehend aus DataVault- und Datamart-Tabellen, parallel installiert und beladen werden.
- Auf jeder Datenmodellschicht können parallel mehrere Schichten mit Fachlogiken gleichzeitig installiert und für Beladungen verwendet werden.
Das Installationsskript des DVG verfügt über verschiedene Modi. Damit können die einzelnen Schichten kopiert (clone), ausgetauscht (swap), gelöscht (drop), migriert (migrate) bzw. neu erstellt (create). werden
Zusätzlich hat das Installationsskript des DVG einen Parameter Level. Damit wird angegeben, welche Schichten betroffen sind:
stage = alle Schichten
modell = Modellschicht mit Fachlogik auf bestehender Stagingschicht
rule = Fachlogik auf bestehender Modellschicht
Intern nutzt der DVG dabei das Zero Copy Cloning von Snowflake. dadurch entstehen trotz vielfältiger Kopien keine hohen Speicherkosten, da Snowflake nicht die Daten, sondern nur die Metadaten kopiert.
Der Clou dabei ist, dass verschiedene DWH-Modelle auf den gleichen Liefersystemdaten in der Stagingschicht installiert werden können. Dadurch können diese Modelle sehr gut miteinander verglichen werden. Alle auftretenden Abweichungen sind ausschließlich durch abweichende Datenmodelle/Fachlogiken verursacht. Abweichungen durch unterschiedlichen Datenstände der Liefersysteme sind unmöglich.
Wie erfülle ich alle obigen Anforderungen gleichzeitig?
- Eine Installation mit
cloneauf Levelstagestellt der Fachabteilung das Release 2.0.0. dauerhaft unverändert zum Testen bereit. Nach Abschluss der Tests wird diese Umgebung wieder gelöscht. - Für Controlling erfolgt eine Installation mit
cloneauf Levelmodell. Anschließend erfolgt mit Modusmigrateeine Migration auf Release 2.1.0 und eine einmalige Testbeladung. Diese kann durch die Controlling-Abteilung geprüft werden. - Für den BI-Bereich wird vor der Produktivnahme von Release 2.0.0 mit Modus
cloneauf Levelmodelldas alte Release kopiert. Diese Kopie wird dann 4 Wochen lang parallel zum neuen Release jeden Tag ebenfalls mit neuen Daten beladen. Der BI-Bereich kann also in einer 4-wöchigen Übergangsphase seine Reports eigenständig und schrittweise auf das neue Release überführen. Nach 4 Wochen wird die Umgebung des Release 1.9.0 gelöscht. - Für Data Science wird im Modus
cloneauf Levelmodelleine Kopie erstellt. Die Data Science Abteilung kann eigenständig entscheiden, ob, wann und wie in dieser Umgebung Datenmodelle angepasst und neue Daten geladen werden. Die Originaldaten der Zuliefersysteme stehen Ihnen dabei immer aktuell in der Staging Schicht zur Verfügung. Wenn das trainierte Modell gute Vorhersagen trifft, werden die Modell-/Logikänderungen in Absprache mit dem Warehouse-Team in das produktive Warehouse übernommen. - Für den Vorstand wird mit
cloneauf Levelmodelleine neue Umgebung erstellt, dort die neue KPI-Berechnung mit dem Modusmigrateinstalliert und für die Vorstandssitzung nächste Woche bereitgestellt. Außerdem wird die neue KPI-Berechnung in das geplante Release 2.1.0 mit aufgenommen. - Für den Stresstest der Bafin wird mit
cloneauf Levelstageeine vollständige Umgebung neu erstellt. In dieser Umgebung werden die im Stresstest zu prüfenden geänderten Marktdaten (z.B. erhöhte Kreditzinsen und vermehrte Kreditausfälle) angeliefert und der geänderte Eigenkapitalbedarf berechnet. - Für den Hotfix wird mit Modus
cloneund Levelruleeine angepasste Fachlogik installiert und getestet. Wenn im Test das Problem nicht mehr auftritt, wird die Hotfixfachlogik gegen die aktuelle Fachlogik mit dem Modusswapund Levelrulegetauscht.
Fazit
Das Multienvironmentkonzept des DVG bietet maximale Flexibilität, um unterschiedliche Anforderungen gleichzeitig und parallel zu erfüllen.
Unterschiedliche StakeHolder mit unterschiedlichen Daten und DWH-Modellen gleichzeitig zu versorgen ist für das DWH-Team kein Problem.
Zusätzlich wird die Eigenverantwortung der verschiedenen StakeHolder gestärkt. Da die verschiedenen Umgebungen unabhängig voneinander sind, können verschiedene StakeHolder eigenständig Änderungen vornehmen, ohne „jede Kleinigkeit“ mit anderen Fachabteilungen abstimmen zu müssen. Im schlimmsten Fall muss nur eine „kaputte“ Umgebung erneut kopiert und bereitgestellt werden. Trotzdem sind Stakeholder nicht gezwungen, sich mit den (meist sehr vielen) Zuliefersystemen des DWH’s abzustimmen, da Ihnen die aktuellen Lieferdaten in der Staging-Schicht jederzeit zur Verfügung stehen.
Damit entsteht für alle Beteiligten eine Win-Win Situation.



