
PPI-Cross-Data-Scientisten Samuel Eucker und Kevin Bernardo entwickeln KI-basierte Methode zum Verstehen großer, unbekannter Textmengen.
Mit Wörtern kann man rechnen. Mit Texten kann man rechnen. Und zwar sehr gut.

Die Bedeutung eines Wortes, eines Satzes oder eines ganzen Dokuments lässt sich in Zahlen ausdrücken. Auch dieser Text würde da keine Ausnahme machen. Man kann sie addieren oder subtrahieren und erhält dann neue Bedeutungen. Man kann sie auch vergleichen und somit herausfinden, wie ähnlich ein Wort, ein Text, dem anderen ist.
Beispielsweise haben wir ein Word2Vec – Modell auf den Texten der deutschen Wikipedia trainiert. Mithilfe des Modells können wir nun mit Wortvektoren (= Zahlen) rechnen. Aus den Vektoren für „Dollar“ plus „EU“ minus „USA“ wird (ungefähr) der Vektor von „Euro“. Oder wir erfahren, dass das von der Bedeutung her nächstähnliche Wort zu „EZB“ die „Bankenaufsicht“ sei. Ähnlich kann man auch mit längeren Texten bzw. Dokumenten verfahren, wobei sich in dem sogenannten Dokumentvektor andere Bedeutungsaspekte niederschlagen als in den Wortvektoren.

Berge von Texten gibt es überall
Wenn so etwas mit einzelnen Texten möglich ist, wie sieht es dann aus, wenn man eine große Anzahl unbekannter Texte vorliegen hat? Tatsächlich ist diese Situation gar nicht ungewöhnlich: Mails, Telefongespräche, Briefe, prinzipiell jegliche Art von Kommunikation, Nachrichten aller Art, Onlineformulare, Freitextfelder in Datenbanken, Anzeigen, Umfragen – dies sind alles große Ansammlungen von ungelesenen Texten.
Wir haben nach einer Lösung gesucht, wie man verstehen kann, worum es in den vielen Texten einer großen Textsammlung (auch Korpus genannt) geht, ohne sie lesen zu müssen. Abgesehen von diesem Text, den Sie lesen müssen, um zu verstehen, wie das vonstattengeht. Warum stellen wir uns diese Aufgabe? Bei 1000 Texten à 100 Wörtern kann man locker zehn Tage pure Lesezeit einsparen, wenn man sie nicht lesen muss.
Die Lösung besteht darin, mithilfe einer KI-basierten Methode vier Fragen über eine Textsammlung zu beantworten:
- Wie viele Themen liegen in den Texten vor?
- Welche sind dies?
- Was ist im Bezug zur Textsammlung ein gewöhnlicher Text?
- Was ein ungewöhnlicher?
Um diese Fragen zu beantworten, verbinden wir zwei Methoden aus dem Bereich der automatischen Verarbeitung natürlicher Sprache – engl. Natural Language Processing (NLP), nämlich semantisches Text-Clustering und semantische Ausreißersuche. Das Clustering beantwortet die ersten beiden Fragen, die Ausreißersuche die letzten beiden. Beides sind Methoden, die in der NLP-Forschung schon seit einer Weile angewendet werden, doch besteht die Herausforderung darin, verlässliche und gut interpretierbare Ergebnisse zu erhalten. Nun möchten wir die beiden Methoden etwas genauer beleuchten.
Clustering
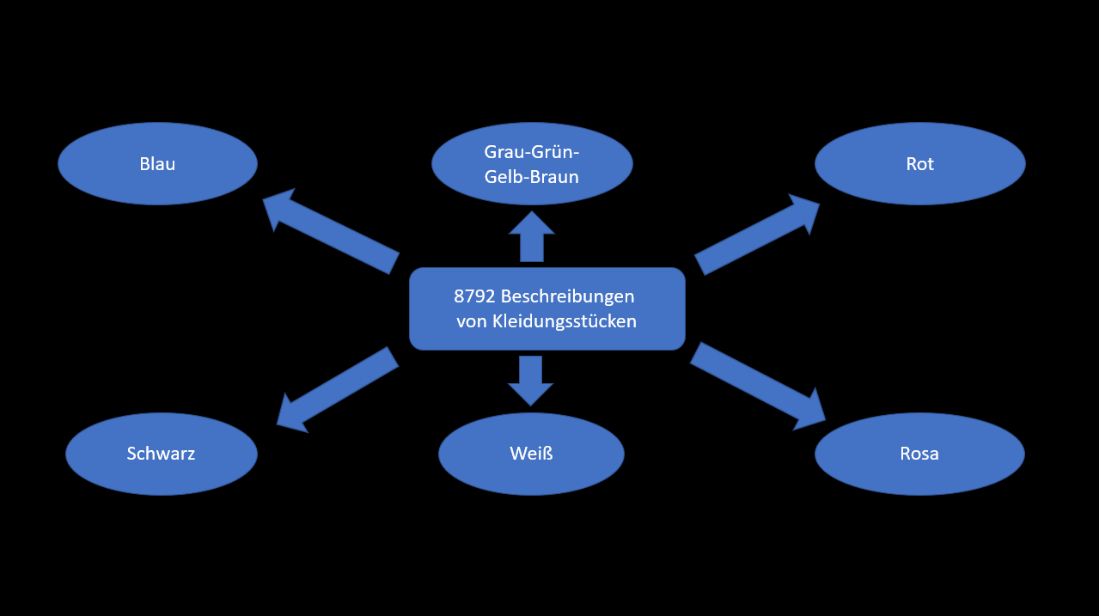
Der Zweck des Text-Clusterings ist es, die Anzahl von verschiedenen Themen im Textkorpus und die Themen selbst zu identifizieren. Wir haben unseren Ansatz mit einem frei verfügbaren Datensatz getestet. Dieser enthält Beschreibungen von 8792 Kleidungsstücken. Mithilfe des Clusterings identifizieren wir 6 verschiedene Themen in dem Datensatz.
Wie kommen wir auf diese 6 Themen?
Zuerst wandeln wir die Texte in Zahlenvektoren um. Dann ordnen wir sie mithilfe eines Clustering-Algorithmus einem Cluster zu. Damit ist die Anzahl der Themen und Zuordnung der Texte zu Themenclustern klar. Wir wissen, dass Texte, die in demselben Cluster sind, gewisse Gemeinsamkeiten haben. Doch müssen wir noch herausfinden, was das Thema der Cluster, also die Gemeinsamkeit der darin enthaltenen Texte, ist. Dazu könnten wir die Texte lesen oder überfliegen, die in ein Cluster fallen.
Aber auch dieser Schritt lässt sich automatisieren, indem Schüsselwörter für ein Cluster mit Methoden aus dem Bereich der Explainable AI identifiziert werden. Das Ergebnis ist eine intuitive Sicht auf die verschiedenen Themen im Korpus.
Die Texte wurden nach den Farben der Kleidungsstücke sortiert. Es ist auch tatsächlich so, dass verschiedene Farben in fast jedem Text des Korpus eine Rolle spielen und die Farben somit ein gutes Unterscheidungsmerkmal abgeben. Der Clustering-Algorithmus hat somit nachvollziehbar gearbeitet. Er hat aber die Eigenart, dass er nicht weiß, welche Informationen für den Betrachter relevant sind. Mit dem Vorwissen, dass ein Korpus mit Beschreibungen von Kleidungsstücken vorliegt, ist die Erkenntnis, dass die Kleidungsstücke verschiedene Farben haben, eher uninteressant.
Indem wir alle Erwähnungen von Farben aus den Texten entfernen, zwingen wir den Algorithmus, andere Unterscheidungsmerkmale zu finden. So kommen wir zu einem weiteren Clustering. Nun wurden die Texte nach verschiedenen Kleidungstypen sortiert. Potenziell könnte man diesen Schritt mehrfach anwenden und so weitere Ebenen und Themen in den Daten aufdecken.
Clustering hat die Eigenart, dass man nicht grundsätzlich sagen kann, dass es falsch oder richtig ist. Wir denken es ist angemessen, auf die Nützlichkeit der Information zu schauen. Das kann auch bedeuten, dass wir verschiedene Sprachmodelle nutzen, um verschiedene Clusterings zu erzeugen. Von diesen ist dann keines unmittelbar der Gewinner, sondern sie sind mehr oder weniger nützlich für den jeweiligen Anwender.
Clustering ist ein gutes Werkzeug, um Themen in textuellen Daten zu entdecken. Eine umfassende Analyse bietet es nicht, aber einen Startpunkt für diese. Der unvoreingenommene, kontextfreie Blick der Maschine auf die Daten kann helfen, Aspekte zu erkennen, die ein Mensch nicht in den Vordergrund gestellt hätte. In Kombination mit der Ausreißersuche gewinnen wir eine umfassende Sicht auf die Textdaten.
Ausreißersuche
Bei der Ausreißersuche geht es darum, alle Texte einer Sammlung nach ihrer Gewöhnlichkeit oder Ungewöhnlichkeit in Bezug zur Gesamtheit zu sortieren. Der Text auf Position eins wäre für uns der ungewöhnlichste und der auf der letzten Position der gewöhnlichste, typischste Text. Im folgenden Beispiel haben wir dem Kleidungsartikel-Korpus absichtlich ungewöhnliche Texte aus anderen Sammlungen, wie Zeitungsartikel und Kundenbewertungen zugefügt. Die Erwartung an die Methode ist, dass diese Texte als ungewöhnlich eingestuft werden, also auf niedrige Positionen gelangen. Diese Erwartung wurde in diesem Fall gut erfüllt.
Um zu prüfen, dass die Ausreißersuche verlässlich funktioniert, wurde dieser Vorgang randomisiert wiederholt. Dabei hat sich gezeigt, dass man mit unserer aktuellen Lösung im Schnitt nur die ersten 12% der Texte in einem Korpus lesen muss, um 90 % der Ausreißer zu finden. Betrachtet man nur Korpora, welche eine substanzielle inhaltliche Homogenität aufweisen, so lässt sich diese Zahl auf unter 10% drücken.
Die so gewonnene Information ist sehr nützlich. Man sieht auf einen Blick ungewöhnliche Einträge und man lernt, welche Einträge nichts Besonderes sind, also erkennt man, worin der Tenor einer Textsammlung besteht.
Was steckt technisch hinter der Ausreißersuche? Kurz gesagt: ein Autoencoder. Der Autoencoder ist ein neuronales Netzwerk, das für viele verschiedene Daten, nicht nur Texte, zur Ausreißersuche dienen kann. Wir haben dieses Prinzip für Texte adaptiert. Schreiben Sie uns gerne für detaillierte Erläuterungen.
Was kann man damit noch machen?
Nun wissen wir, welche Themen vorliegen und was die ungewöhnlichen Texte sind. Wir finden, dass das alles ist, was man braucht, um zu wissen, worum es bei einer Textsammlung geht.
Auf diese Informationen können nun automatische Prozesse aufgebaut werden. Dazu ein kleines Beispiel:
Nehmen wir an, ein weiterer Text kommt herein, zum Beispiel in Form einer E-Mail von einem Kunden. Dieser Text kann nun durch eine Klassifikation automatisch einem der Themen zugeordnet werden, welche durch das Clustering ermittelt wurden. Damit ist klar, welche Abteilung sich um die E-Mail kümmern wird und die E-Mail wird automatisch an diese weitergeleitet.
Weiterhin kann durch die Ausreißersuche bewertet werden, wie ungewöhnlich der Inhalt der E-Mail ist. Ist sie ungewöhnlich, erhält sie automatisch eine erhöhte Priorität in der weiteren Bearbeitung. Hier kommen noch weitere Methoden aus dem NLP-Werkzeugkoffer in den Sinn, wie die Sentiment-Analyse, welche in Kombination mit den genannten Informationen noch genauere Justierungen des Prozesses erlauben. Letztendlich wird so erreicht, dass wichtige Informationen automatisch richtig eingeordnet werden.
Zusammengefasst
Mit KI-basierten Methoden für das Verstehen großer, unbekannter Textmengen kann man sehr viel Lesezeit sparen und wertvolle Informationen über die Texte generieren. Diese Informationen tragen dazu bei, Prozesse im Sinne des Kundennutzens zu gestalten. Dem Weg zur Data Driven Organization steht damit nichts mehr im Wege!

Kevin Bernardo
Kevin ist Data Scientist und dualer Student bei PPI. Er hat einen Bachelorabschluss in Informatik und studiert jetzt Master Data Science an der Hochschule Darmstadt. Bei crossnative hat er sich als Experte in Fragen des Natural Language Processing (NLP) einen Namen gemacht. Im Bereich NLP entwickelt Kevin unter anderem Anwendungen für Text Clustering und Question Answering.

Samuel Eucker
Samuel ist Data Scientist, Volkswirt und Scrum Master. Im Bereich Data Science vertieft er sich aktuell in Fragen der Verarbeitung natürlicher Sprache. Außerdem ist er Experte rund um das Thema der Datenqualität, sei es DQ Monitoring oder auch Master Data Management. Spannend wird es, wenn NLP und Datenqualität aufeinander treffen! Samuel bringt Branchenwissen aus den Bereichen Banken und Telekommunikation mit.


